Lecture 11
• Traditional Unsupervised Learning
• Clustering method: k-means
Lecture 12
• Traditional Unsupervised Learning
• Principal Component Analysis (PCA) 주성분 분석
• :Dimensionality Reduction 차원 축소
Lecture 13
• Tutorials of
kMeans (Image Segmentation)
kMeans (Image Segmentation) k 평균 알고리즘
나의첫 4.7장 p.140~149
3차 과제


Classification(지도학습-분류)은 label 개수가 정해져있지만
Clustering(비지도학습-군집화)은 label 개수가 미리 정해져있지 않음.
군집화
비지도학습의 일종으로, 데이터의 특징만으로 비슷한 데이터들끼리 모아 군집된 클래스로 분류함.
k 평균 알고리즘
데이터 간의 거리를 사용해 가까운 거리에 있는 데이터끼리 하나의 클래스로 묶는 알고리즘.
k는 몇 개의 클래스(집단)로 분류할 것인지를 나타내는 변수임.

- 데이터 준비
- 몇 개의 클래스(cluster)로 분류할 것인지 설정
- 클러스터의 최초 중심(centroid) random으로 설정
- 데이터를 가장 가까운 클러스터로 지정
- 클러스터 중심을 클러스터에 속한 데이터들의 가운데로 위치 변경(new centroid)
- 클러스터 중심이 바뀌지 않을 때까지 4번부터 5번 과정을 반복적으로 수행
k가 클수록 sophisticated 하게 분류됨.
* k값?




kMeans Summary
K-means algorithm is an unsupervised learning method, used for data clustering tasks
The k-means algorithm performs clustering by initializing the data with random k centroids,
then iteratively updating the clusters (based on the distance from centroids)
and centroids (by averaging each cluster) until convergence(수렴)
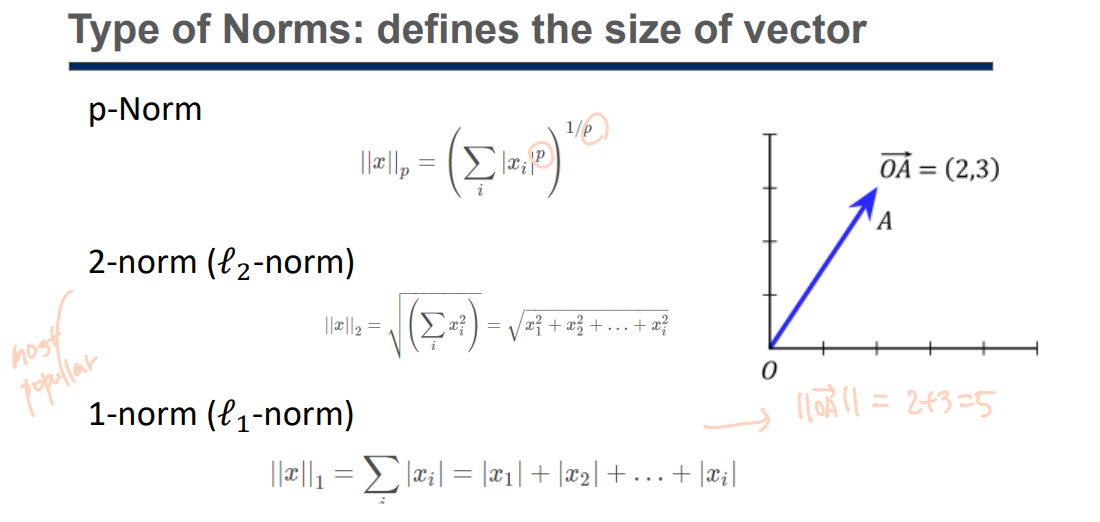
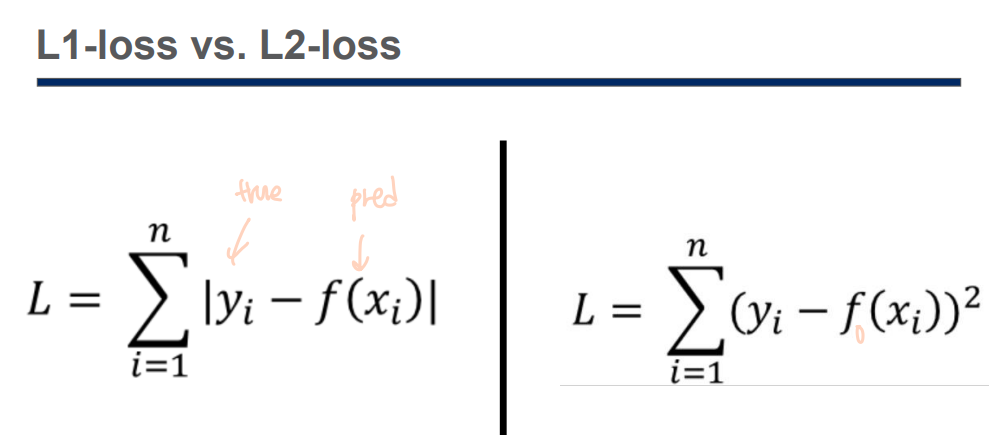
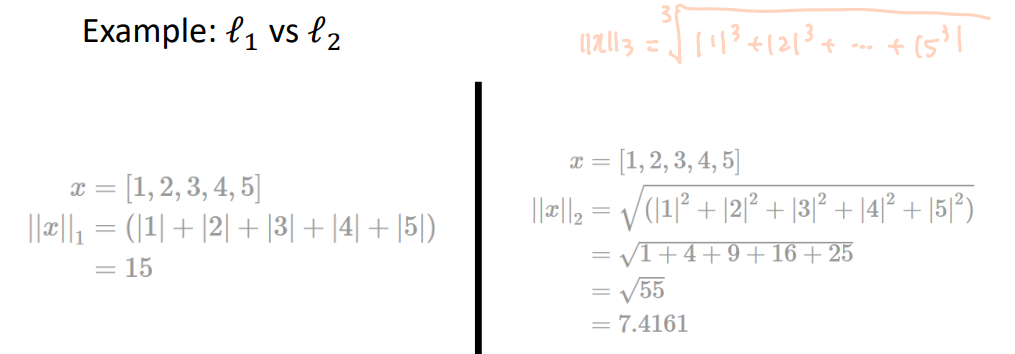
Principal Component Analysis (PCA) 주성분 분석
https://skyil.tistory.com/m/171
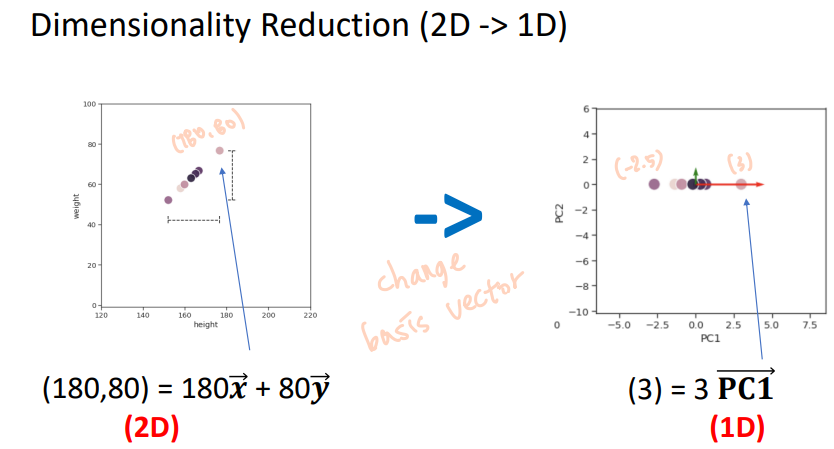
Dimensionality Reduction 차원 축소
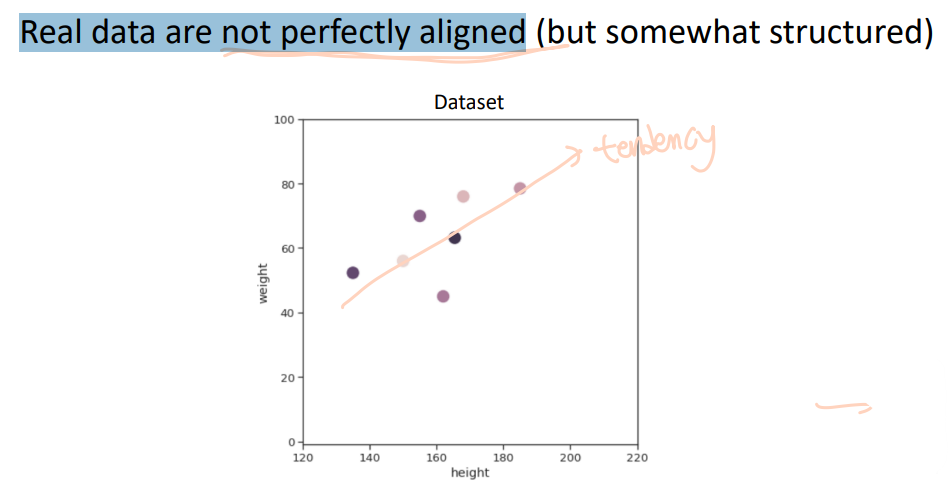
Real data: High Dimensional -> very slow (Computationally heavy)
We want to find a lower dimensional representation of the data
(while maintaining the performance of machine learning)
-> 정확도는 조금 떨어지더라도 매우 빠름.
PCA

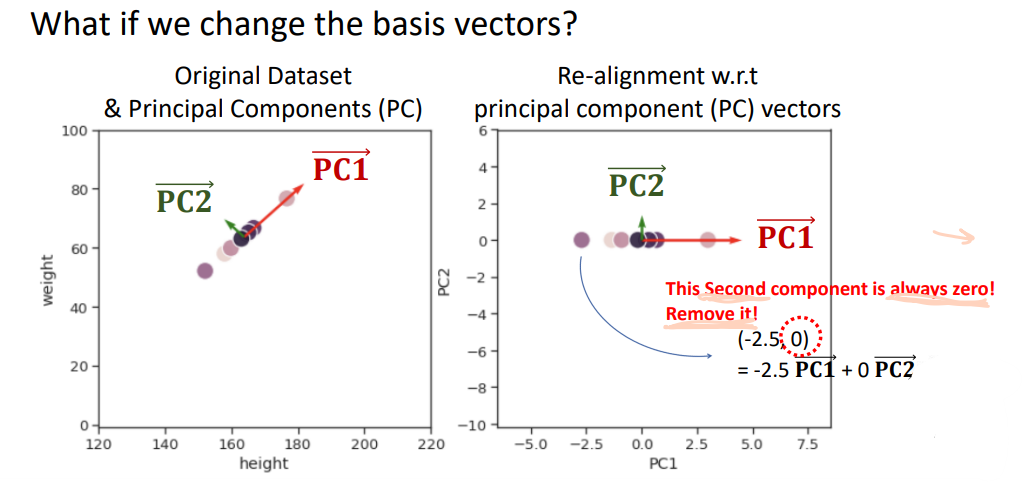
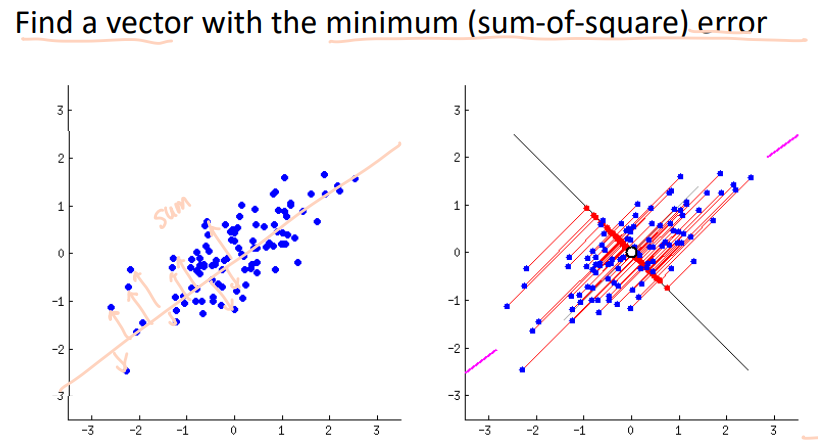
How to find the principal components(주성분)?
In Linear Algebra, it has been shown that
Singular Value Decomposition (SVD) provides the principal components
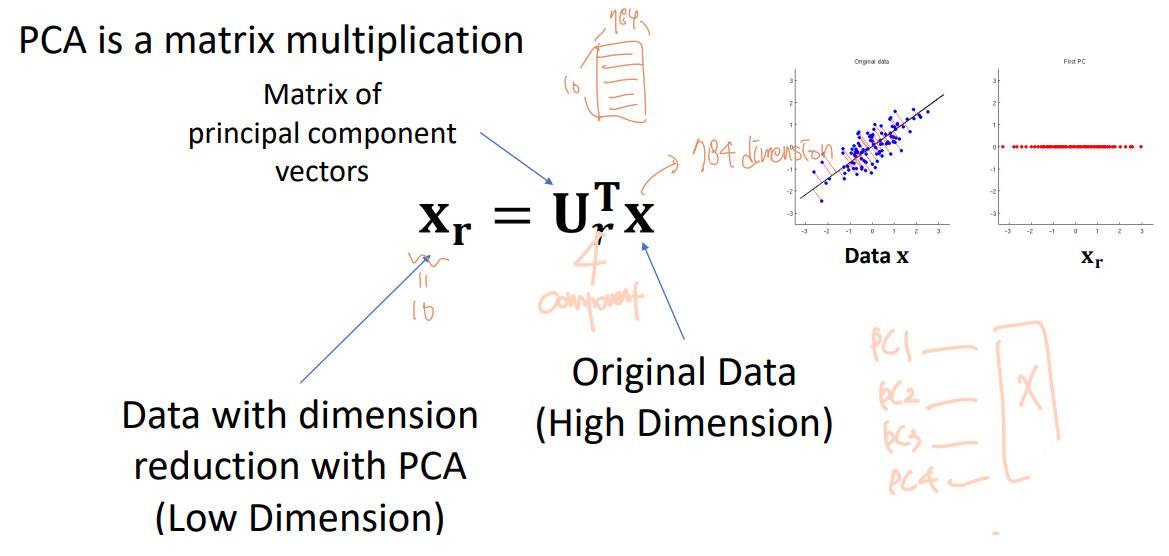
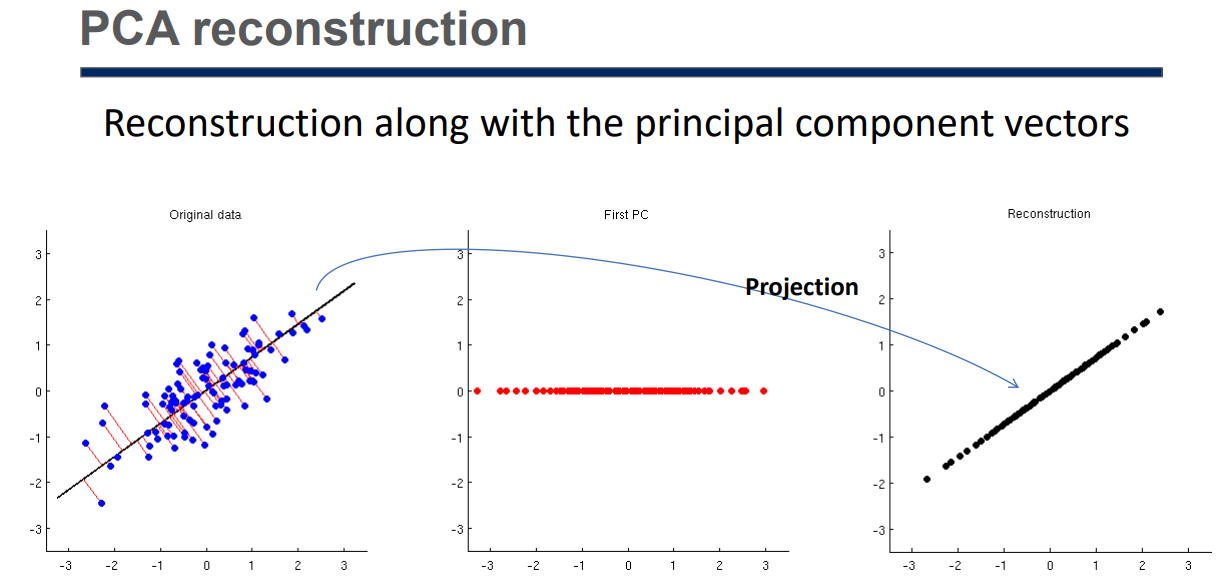
PCA Usage

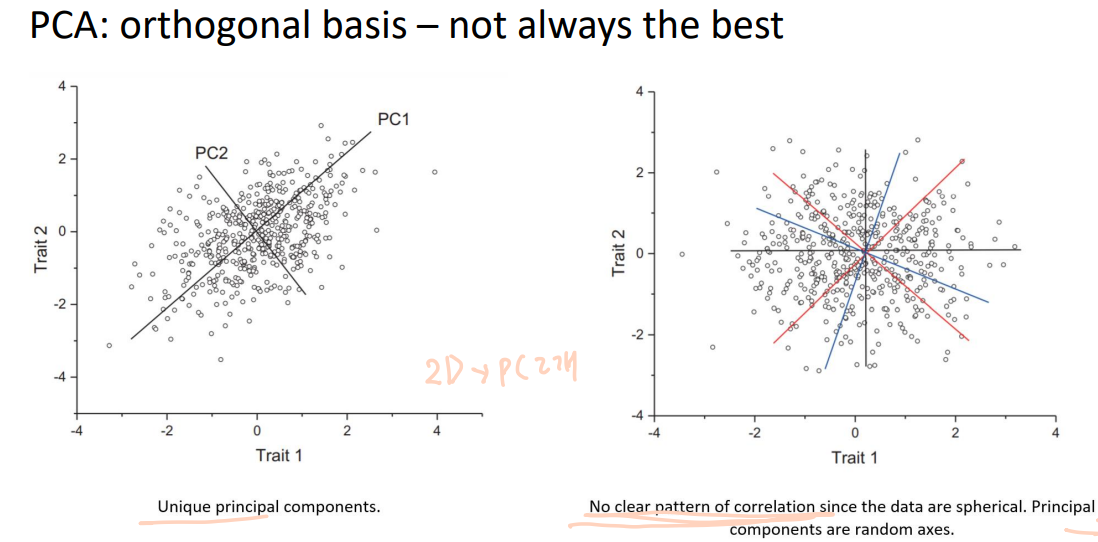
Limitations of PCA
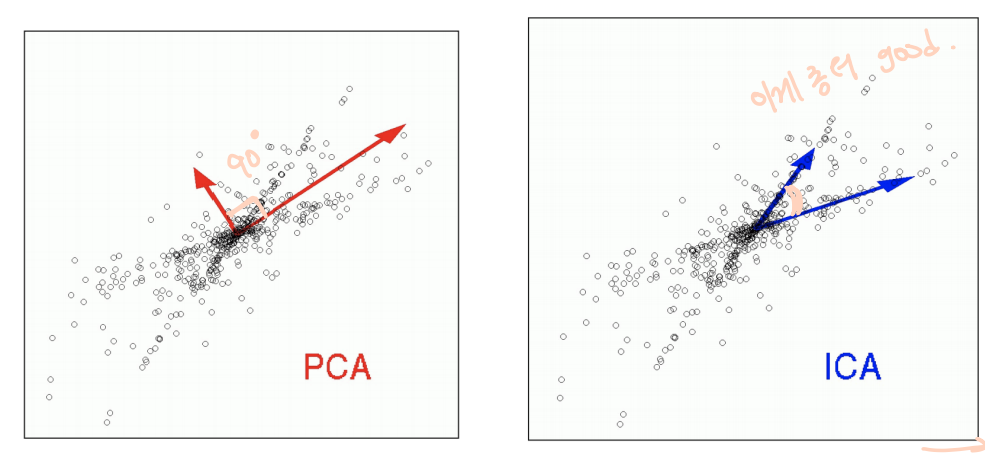
PCA Summary
Principal Component Analysis (PCA) algorithm is an unsupervised learning method,
used for dimension reduction of the data (Data compression)
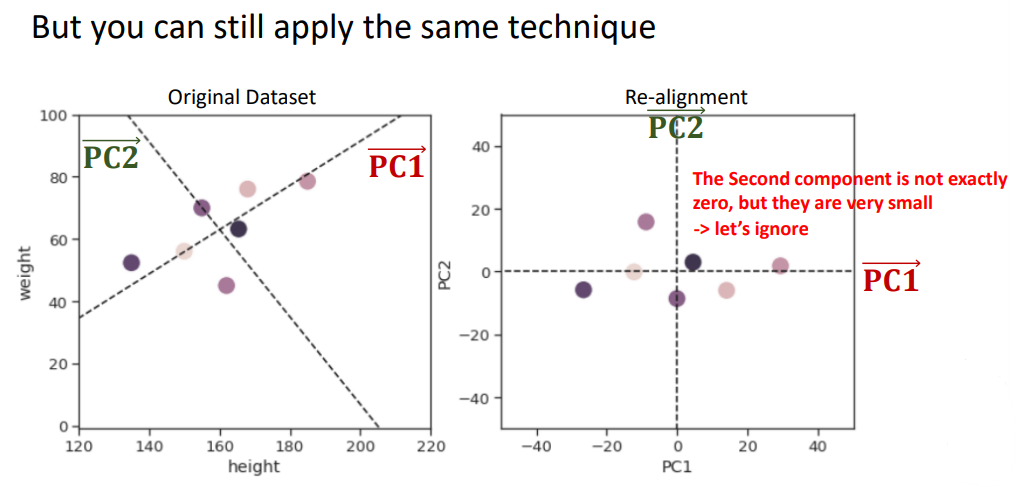
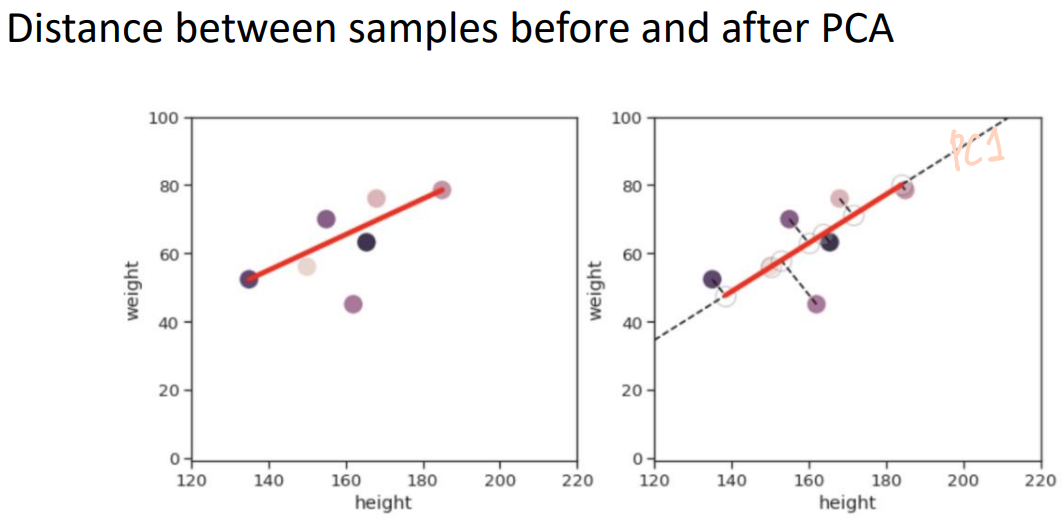
PCA finds the orthogonal principal component vectors and represents the data with respect to those principal components,
which enables the low-dimensional representation of the data
PCA saves computation and memory in machine learning (data가 too big일 때 고려해보자!)
'CS > 3-2 딥러닝' 카테고리의 다른 글
| [비디오이미지프로세싱] 17. Convolutional Neural Networks (0) | 2022.10.19 |
|---|---|
| [비디오이미지프로세싱] 14~16. Loss Function & Optimization, Neural Networks & Backpropagation (0) | 2022.10.19 |
| [비디오이미지프로세싱] 08~10. Support Vector Machine (1) | 2022.10.19 |
| [비디오이미지프로세싱] 05~07. Stochastic Gradient Descent, K-Nearest Neighbors (0) | 2022.10.19 |
| [비디오이미지프로세싱] 03~04. Linear Regression, Gradient Descent (0) | 2022.10.18 |




댓글