Lec 14. Pipeline MIPS_3 (The Processor)
- Dependencies (lec 12 참고)
② Data Hazards
: 두개의 인접한 명령어 사이에 존재하는 data의 dependency로 인해 발생(데이터 의존성).
* 해결책1 : Forwarding (or Bypassing)
* 해결책2 : Code Scheduling to Avoid Stalls
③ Control Hazards
: 조건의 참/거짓을 알아야 다음 명령어를 알 수 있음.
* 해결책1 : Add hardware in ID stage
* 해결책2 : Delayed Branch

- ② Data Hazards
* 해결책1 : Insert nop (0x0000_0000)


-> 기능적으로는 문제없지만 성능적으로 2cycle 손해봄
* 해결책2 : Code Scheduling
reorganize the code so that it relieves the dependencies between instructions
-> 항상 가능한 건 아님
* 해결책3 : Forwarding (or Bypassing)
don't wait for them to be written to the register file (use temporary results)
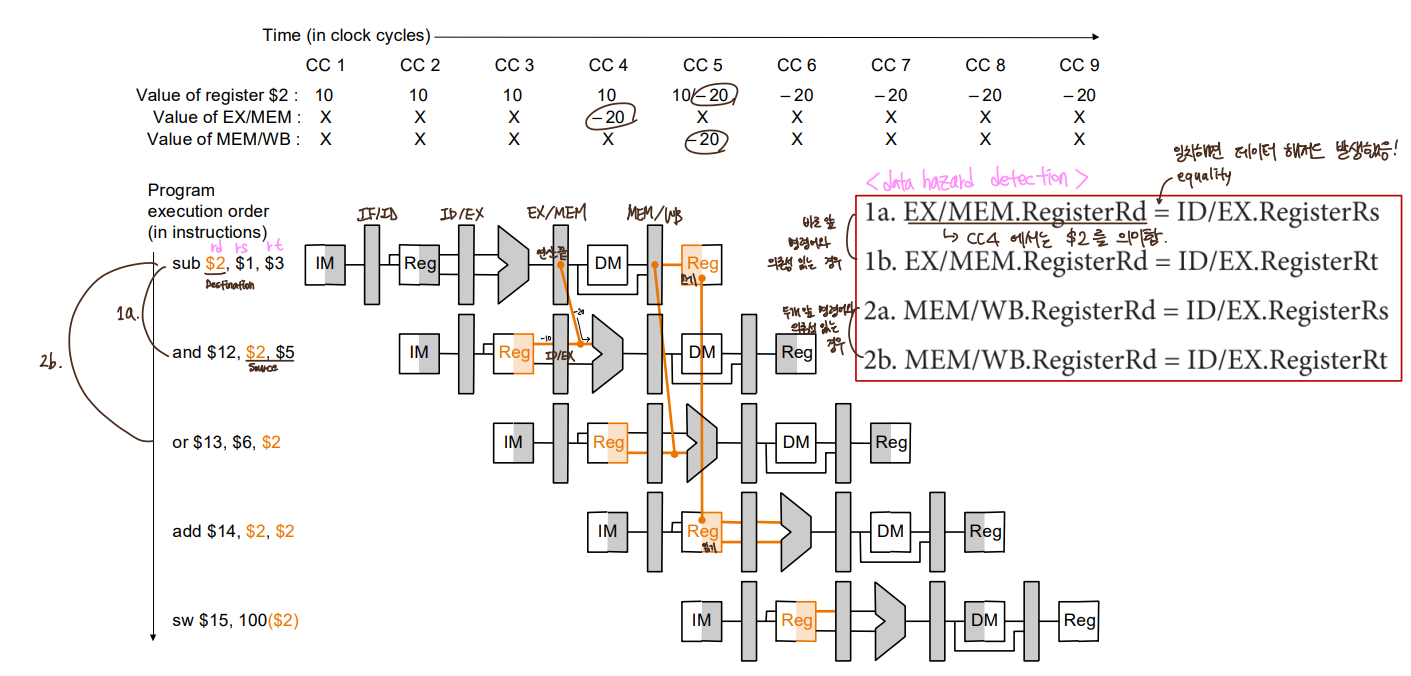
1a,1b. 바로 앞 명령어(EX/MEM)의 Rd와 현재 명령어(ID/EX)의 Rs(or Rt)가 같다면
데이터 해저드 발생! => EX hazard
2a,2b. 두개 앞 명령어(MEM/WB)의 Rd와 현재 명령어(ID/EX)의 Rs(or Rt)가 같다면
데이터 해저드 발생! => MEM hazard



-> 한개 또는 두개 앞 명령어가 쓰기 동작을 하고, 그 대상이 0번 레지스터가 아니고,
Destination이 내가 Source로 활용하려는 대상과 동일하다면
Forwarding을 함.

=> 근데 MEM hazard 이려면 EX hazard가 아니라는 조건이 추가로 붙어야함



- Load-Use Case (lec 12의 data hazard 해결책2 참고)
: Can't always forward. lw still cause a hazard

-> hazard detection unit 이 "stall" the pipeline 해줘야함.

1) load-use case hazard detect
2) decode 단계까지 가져온 명령어를 nop화(무효화)
3) 지금 가져온 명령어부터 그 다음에 있는 모든 명령어들을 한 cycle 씩 미룸


- ③ Control Hazards
* 해결책1 : Add hardware in ID stage
* 해결책2 : Delayed Branch
* 해결책3 : Branch Prediction
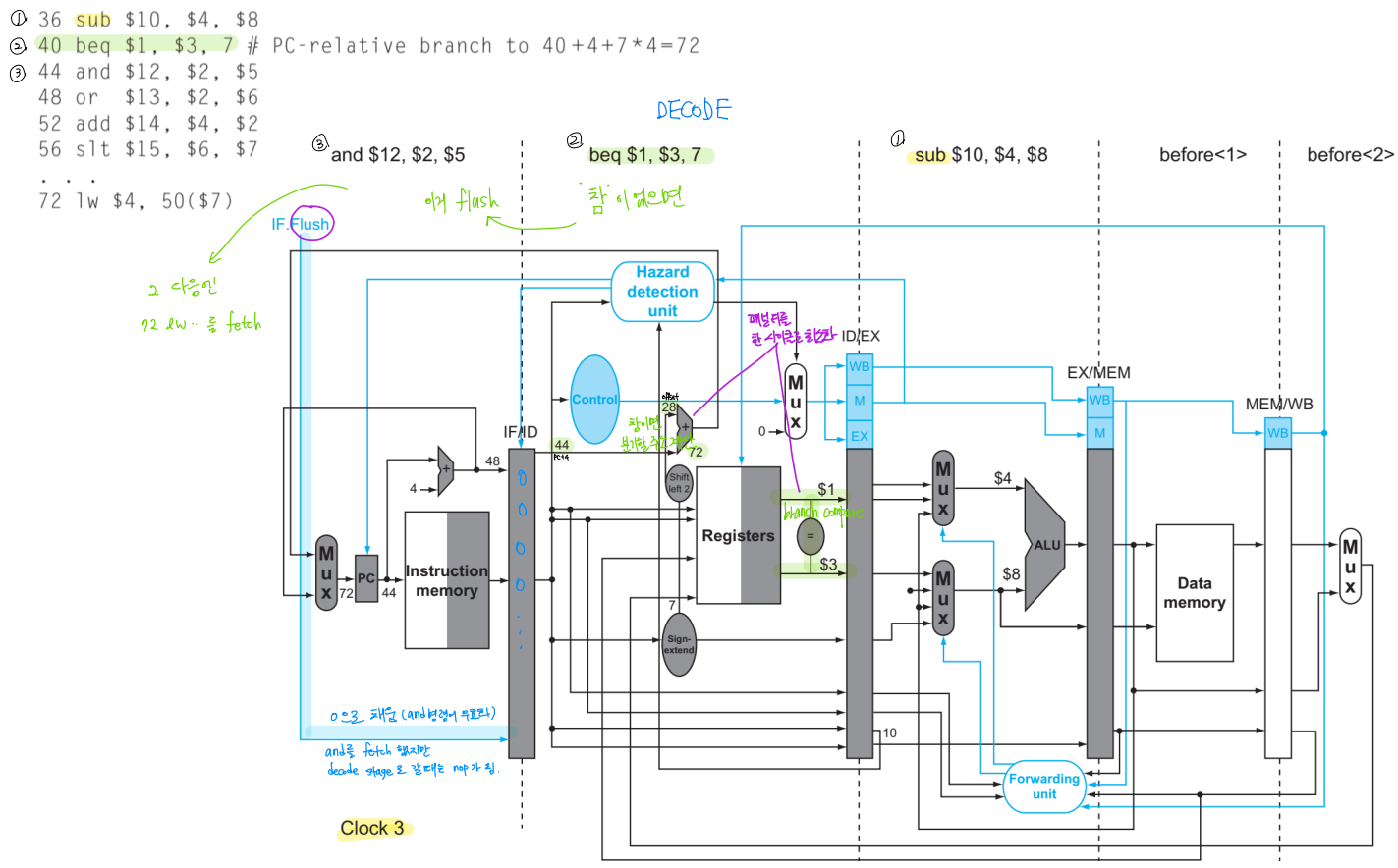
일단 거짓이라고 예상, 예측 틀렸으면(참이었으면) 명령어 flush

2 bubbles -> Add hardware in ID stage -> 1 bubble (lec12 ③-1 참고)
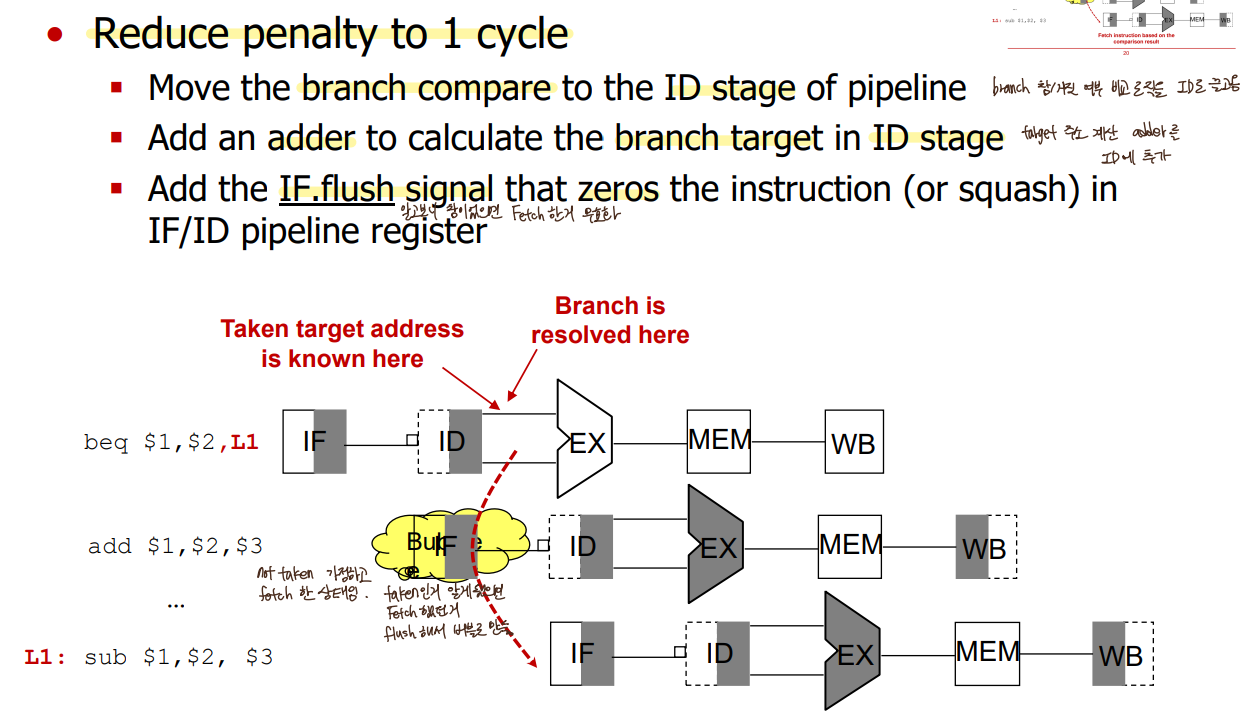
ex) Alleviate Branch Hazards


- Performance of Pipelined CPU
CPU Time = # insts X CPI X clock cycle time (T) = # insts X CPI / f
* CPI : AVG. clock cycles per inst (명령어 당 사이클 수)
Ideally CPI = (5+1...+1)/n ≒ 1 (실제로는 hazard 때문에 stall하느라 CPI가 1보다 커짐)
ex1) hazard 없는 경우 (이상적)
- 명령어 분포
25% loads
10% stores
11% branches
2% jumps
52% R-type
=> Average CPI = (0.25) (1 CPI) + (0.10) (1 CPI) + (0.11) (1 CPI) + (0.02) (1 CPI) + (0.52) (1 CPI) = 1
ex2) hazard 있는 경우 (현실적)
- 명령어 분포
25% loads (40% of loads are used by next instruction)
10% stores
11% branches (25% of branches are mispredicted)
2% jumps (All jumps flush next instruction)
: decode까지 가야 타겟주소 계산되고 거기로 무조건 분기해야함 -> 100% 패널티 있음.
52% R-type
Load/Branch CPI = 1 when no stalling, 2 when stalling. Thus
CPIlw = 1 (0.6) + 2 (0.4) = 1.4
CPIbeq = 1 (0.75) + 2 (0.25) = 1.25
CPIjump = 2 (1) = 2
=> Average CPI = (0.25)(1.4) + (0.1)(1) + (0.11)(1.25) + (0.02)(2) + (0.52)(1) = 1.15
- Exceptions & Interrupts (시험x)

'CS > 3-1 컴구' 카테고리의 다른 글
| [컴퓨터구조] #16. Cache(2) (0) | 2022.06.03 |
|---|---|
| [컴퓨터구조] #15. Cache(1) (0) | 2022.05.29 |
| [컴퓨터구조] #13. Pipeline MIPS(2) (0) | 2022.05.13 |
| [컴퓨터구조] #12. Pipeline MIPS(1) (2) | 2022.05.11 |
| [컴퓨터구조] #11. Single-Cycle MIPS(2) (3) | 2022.04.23 |




댓글