
[컴퓨터구조] #15. Cache(1)
Lec 15. Cache_1 (Large and Fast: Exploiting Memory Hierarchy)
- CPU vs Memory Performance
CPU 성능 : 1.5년마다 2배의 속도로 성장
DRAM 성능 : 10년마다 2배의 속도로 성장
-> 성능 격차⬆
-> memory wall : 컴퓨터 시스템의 성능을 끌어올리는데 메모리가 벽(장애)으로 작용
- Memory Wall
: CPU와 DRAM의 성능격차가 점점 커져서, 성능 결정이 거의 메모리에 의해서 됨.
-> memory hiearchy design(메모리를 계층적으로 설계) 이 중요해짐.
ex) SRAM(속도⬆,가격⬆) - DRAM - Magnetic disk(속도⬇, 가격⬇)

- Cache
: small memory inside processor, SRAM-based memory(속도⬆,가격⬆,용량⬇)
CPU와 DRAM의 속도 차이 줄여줌, 하드웨어가 운용함
- SRAM(Cache) vs DRAM
SRAM : 빠름(∵CPU내부), DRAM보다 트랜지스터 많이 필요함, 캐시로 사용
DRAM : SRAM보다 트랜지스터 적게 필요함, 느림(∵CPU외부), 메인메모리로 사용
L1 : private cache. Core마다 따로 존재, 작음
L2 : shared cache. 공유, 큼
- A Typical Memory Hierarchy
: take advantage of the principle of locality
(user 입장에서는 마치 굉장히 크고 빠른 메모리를 쓰고있는 것과 같은 착각을 일으킬 수 있는 원리)
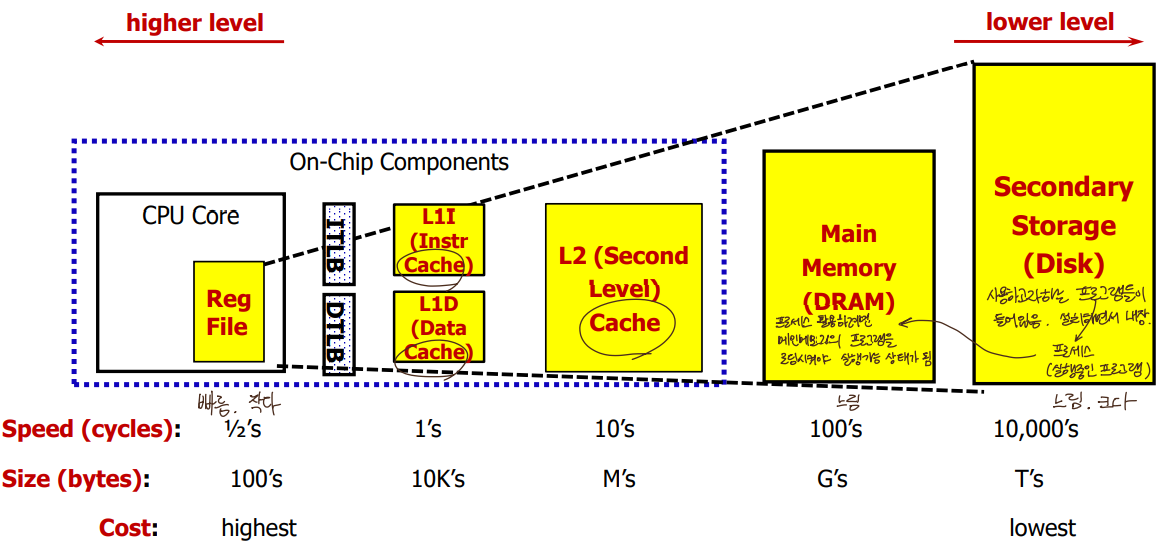
- How is the Hierarchy Managed?
Registers ↔ Main memory : compiler(and programmer)가 관리(특정위치 지정가능)
Cache ↔ Main memory : hardware(cache controller)가 관리
- Basic Cache Operation

Cache line(block) : 캐시와 메인메모리 사이에 주고받는 데이터크기 단위,
한 번 데이터를 가져올 때 block 크기만큼 통째로 가져옴.
- Why Caches Work?
Locality
: 메인 메모리에 비해 캐시의 크기는 작은데, CPU가 load 요청 할 때마다 가급적 캐시에 들어있도록(속도⬆) 하는 원리
1) Temporal Locality (locality in time)
x번지에 접근했으면 그 프로그램은 미래에 또 x번지에 접근할 확률 높음.
가장 최근에 접근했던 data는 가급적 cache에 계속 둬야함.
2) Spatial Locality (locality in space)
x번지에 접근했으면 그 프로그램은 미래에 그 이웃(근처)번지에 접근할 확률 높음.
메모리 근처 data도 같이 cache로 가져옴.
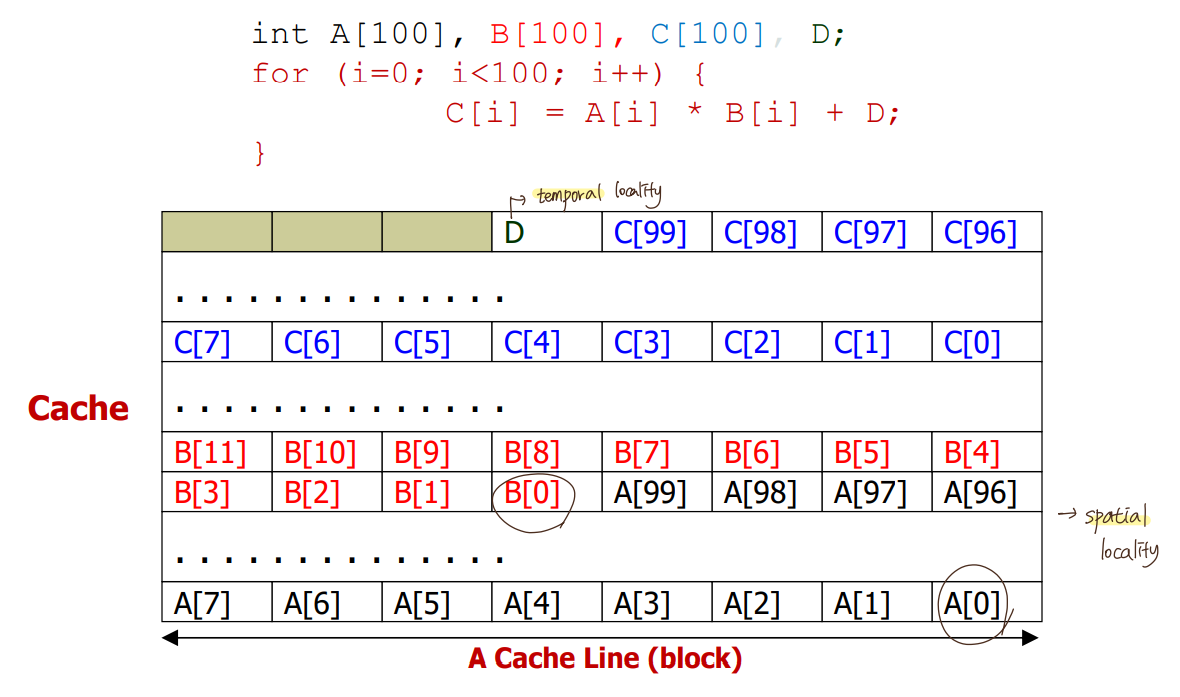
- Cache Terminology
Block (Cache line) : minimun unit of data present in a cache.
cache와 메인메모리 사이에 주고받는 data크기의 단위.
ex) 64B/block 이면 4byte만 읽겠다고 요청해도
해당 4byte를 포함해서 64byte값을 메인메모리에서 cache로 가져옴.
Hit : if the requested data is in cache, it is called a hit
Hit rate : the fraction(비율) of memory accesses found in caches
Hit time : the time required to access the data found in cache
Miss : if requested data is not in cache, it is called a miss
Miss rate : the fraction of memory accesses found in caches (= 1 - Hit Rate)
Miss penalty : cache miss가 일어났을 때 cache hit 대비 부가적으로 소요되는 시간

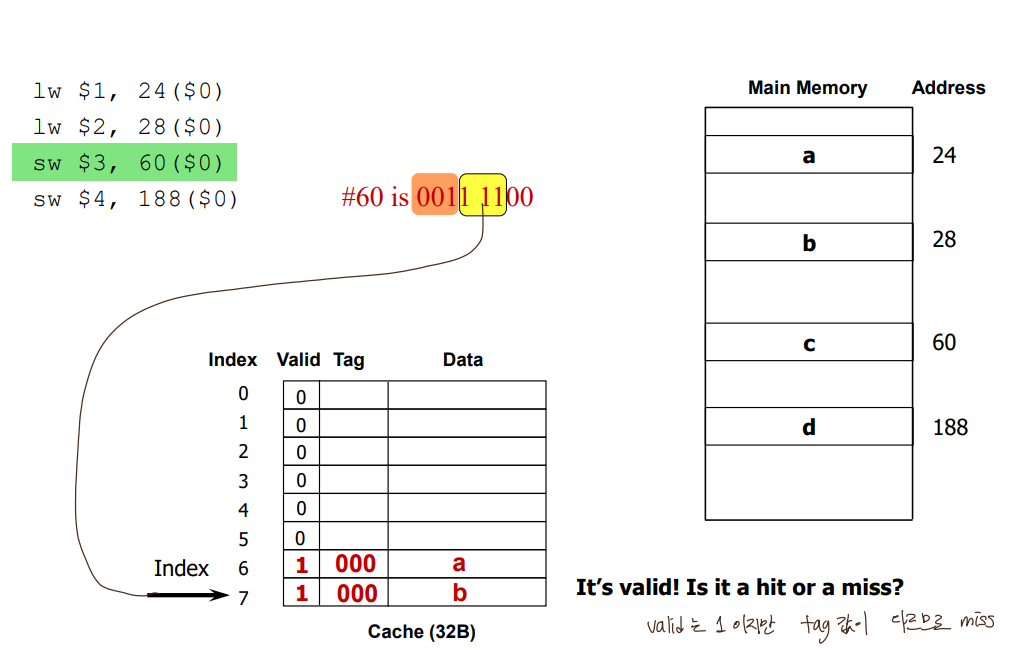
- Direct-mapped Cache
: each memory block is mapped to exactly one block in cache
-> lots of memory blocks must share a block in cache


* block address 나머지 #of blocks in cache : mapping 될 수 있는 cache entry 주소
ex) 01101 나머지 8개(1000) = _ _101
* block address 몫 #of blocks in cache : tag (어느 구역에서 왔는지)
ex) 01101 몫 8개(1000) = 01_ _ _
- Memory Address
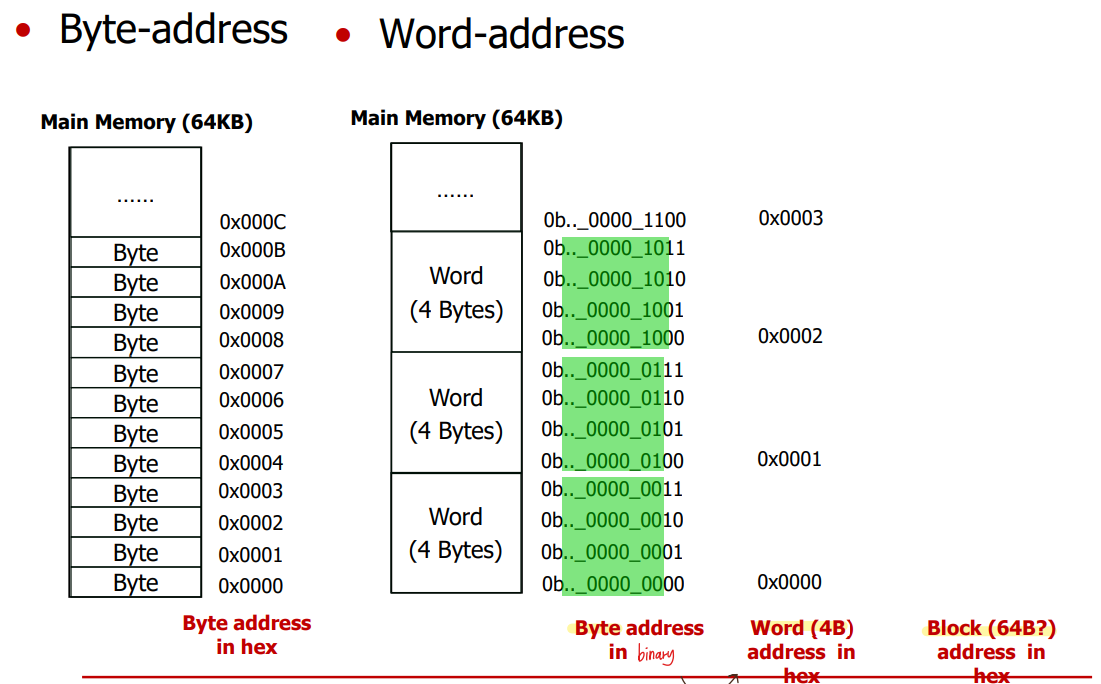

1byte address 에서 2bit 떼어내면 4byte(1word) address 됨.
(예시)
- DM$, 1024-Entry, 4B(1word) blocks

temporal locality만 활용중.
- DM$, 8-Entry, 4B(1word) blocks











- DM$, 1024-Entry, 16B(4word) blocks

byte address에서 2bit 떼어내면 1word address
byte address에서 4bit 떼어내면 block(4word) address
temporal locality와 spatial locality 둘 다 활용중.
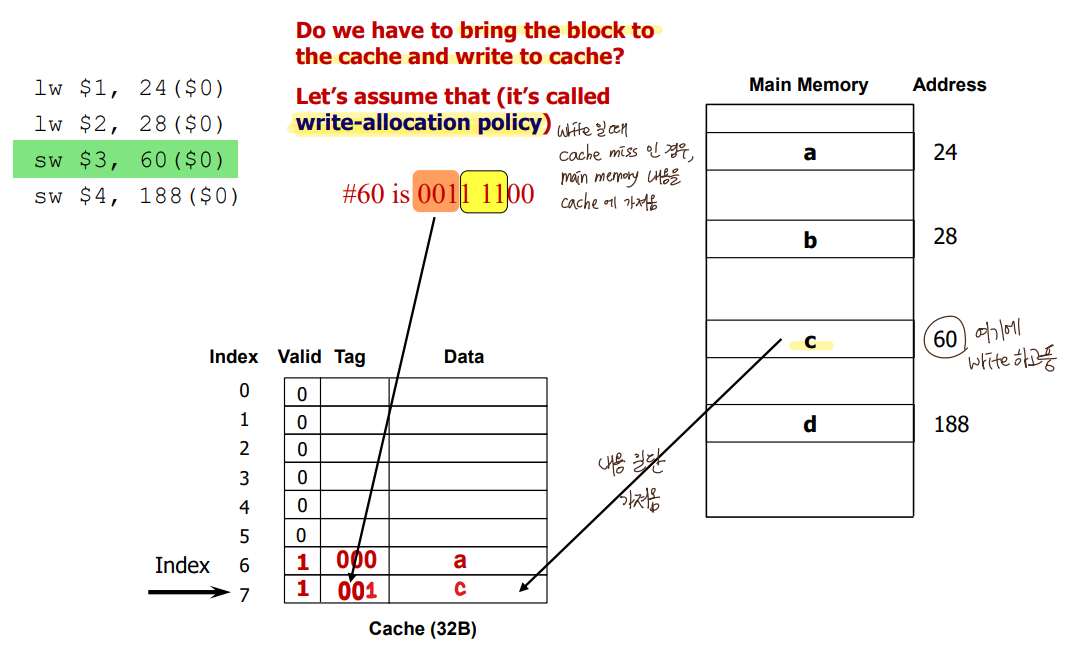
- Handling Writes
read miss : bring the block to cache and supply data to CPU
write miss
-> Upon a write-miss,
1) Write-allocate: bring the block into cache and write
2) Write no-allocate: write directly to main memory without bringing the block to the cache
(굳이 캐시에 공간할당 안함)
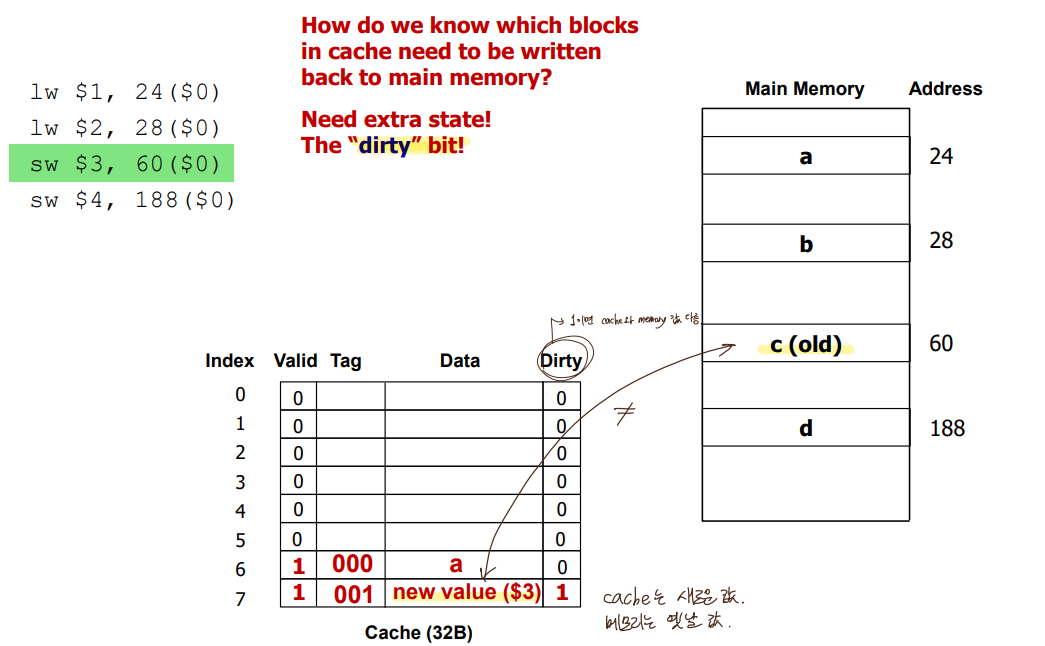
-> When writing,
1) Write-back: update values only to the blocks in the cache and write the modified blocks
to memory(or the lower level of the hierarchy) when the block is replaced,
캐시와 메모리 다를때 dirty bit 세팅
2) Write-through: update both the cache and the lower level of the memory hierarchy
(캐시와 메모리 동시에 업데이트)


- Hits vs Misses
Read hits : This is what we want!
Read misses : Stall the CPU(오랜시간 걸려서 메인메모리까지 가야하므로),
fetch the corresponding (원하는 word 포함된)block from memory,
deliver to cache and CPU, and continue to run CPU
Write hits 1) Write-back cache: write the data only into the cache and set the dirty bit
(and write the block to memory later when replaced). 관리 용이, 성능⬇
2) Write-through cache: write data to both cache and memory
Write misses 1) Write-allocate with write-back: read the block into the cache,
then write the word only to the cache
2) Write no-allocate with write-through: write the word only to the main memory
(without bringing the block to cache)
- Miss Rate vs Block Size vs Cache Size

- Cache Hardware Cost
: cache를 만들려면 공간적으로 몇 bit가 더 필요한지 계산
